728x90
DFS와 BFS의 개념과 구현 공부
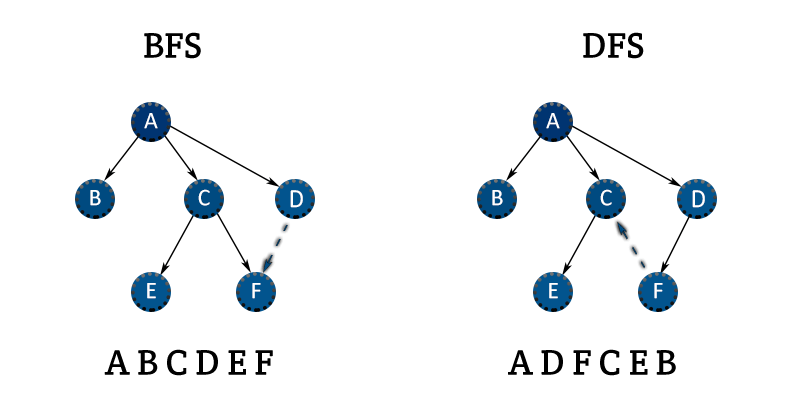
1. DFS (Depth First Search)
- 깊이 우선 탐색이다.
- 한 쪽을 끝까지 파고들고, 더 탐색할 수 없으면 한 노드씩 뒤로 돌아오며 탐색한다.
- 미로 탐색을 생각하면 된다. 한쪽으로 쭉 가다가, 막다른 길이 나오면 바로 전의 갈림길로 돌아가 다른 방향을 탐색한다.
- 탐색 과정에 제약이 있을 경우 DFS로 구현하는 것이 좋다.
1.1 DFS의 특징
1.1.1 DFS 장점
- 파고들고 있는 노드들만 기억하기 때문에 적은 메모리를 사용한다.
- 찾으려는 노드가 깊을 경우, BFS보다 빠르게 찾을 수 있다.
1.1.2 DFS 단점
- 해가 없는 경로를 탐색할 경우에도 단계가 끝날 때까지 탐색한다. (이를 방지하고 효율성을 높이기 위해 미리 지정한 조건까지만 탐색하고 빠져나오는 방식을 사용한다. Backtrack)
- DFS를 통해서 얻은 해가 최단 경로는 아니다.
1.2 DFS의 구현
- 구현이 쉬운 인접행렬을 사용했지만, 노드의 개수가 적을 경우 인접 리스트를 활용하면 보다 빠르게 탐색할 수 있다.
전체 노드의 개수가 V개일 경우, 모든 노드에 방문하고 싶을 경우 총 O(V)의 시간이 걸리기 때문이다. - BFS와 달리 stack을 사용한다.
- 마지막에 방문한 노드를 먼저 버리기 때문이다!
1.2.1 반복문 & 스택 DFS
두 가지 방식이 있다.
V = 7 # 노드의 수
E = 8 # 간선의 수
edges = [1, 2, 1, 3, 2, 4, 2, 5, 4, 6, 5, 6, 6, 7, 3, 7] # 간선 정보
# 인접 행렬 초기화 : 노드 간의 연결관계를 표시하는 2차원 배열
adj = [[0]*(V+1) for x in range(V+1)]
# 인접 행렬에 노드 정보 넣기
for i in range(0, E*2, 2):
s = edges[i]
e = edges[i + 1]
adj[s][e] = 1
adj[e][s] = 1
def dfs(v):
# DFS는 마지막에 방문한 노드가 먼저 버려지므로 스택을 사용한다.
stack = [v]
# 방문 여부를 체크하기 위한 배열
visited = [0] * (V+1)
# v부터 시작하므로 방문했음을 체크
visited[v] = 1
while stack:
# 스택의 맨 위를 바로 빼버린다. (맨 마지막 원소)
# 반복문을 순회하면서 돌 곳이 없으면 한 단계씩 pop하며 스택의 크기가 줄어들고,
# 스택의 길이가 0이 되면 반복문이 종료된다.
top = stack.pop()
print(top, end=" ")
# 해당 노드에서 갈 수 있는 경로가 있는지 탐색
for i in range(1, V+1):
if adj[top][i] and not visited[i]:
stack.append(i)
visited[i] = 11.2.2 재귀 DFS
자기 자신을 호출하는 재귀 알고리즘을 사용하여 구현할 수 있다.
함수 자체의 시스템 콜을 스택이라고 생각하고 구현하는 방식이다.
이 경우 노드의 방문 여부를 체크하는 배열(visited)은 dfs 함수 외부에 선언해 두어야 한다.
재귀의 깊이가 너무 깊어지면 런타임 에러가 날 수 있다.
# 함수를 재귀적으로 참조하기 때문에 외부에 visited 배열을 선언해 둔다.
recursive_visited = [0] * (V+1)
def recursive_dfs(v):
# 현재 정점을 1로 변경
recursive_visited[v] = 1
print(v, end=" ")
for i in range(1, V+1):
if adj[v][i] and not recursive_visited[i]:
recursive_dfs(i)
2. BFS (Breadth First Search)
- 너비 우선 탐색이다.
- 최단 거리를 탐색한다면 BFS를 사용한다.
2.1 BFS의 특징
2.1.1 BFS의 장점
- 답이 되는 경로가 여러 개인 경우에도 최단경로임을 보장할 수 있다.
- 최단 경로가 존재하면 깊이가 무한정 깊어진다고 해도 답을 찾을 수 있다.
2.1.2 BFS의 단점
- 경로가 매우 길 경우에는 뻗어가는 탐색 가지의 수가 급증해 많은 메모리를 필요로 한다.
- 무한 그래프의 경우 해를 찾지 못하고, 끝내지도 못한다.
2.1.3 BFS의 사용
- 웹 크롤링 - 동적으로 생성되는 무한한 웹 페이지 크롤링에 BFS를 사용한다.
- 네트워크 브로드캐스트
- 가비지 컬렉션
2.2 BFS의 구현
- DFS와 달리 queue를 사용한다.
- 먼저 방문한 노드를 먼저 버리기 때문이다!
2.1.1 BFS 코드
V = 7 # 노드의 수
E = 8 # 간선의 수
edges = [1, 2, 1, 3, 2, 4, 2, 5, 4, 6, 5, 6, 6, 7, 3, 7] # 간선 정보
# 인접 행렬 초기화 : 노드 간의 연결관계를 표시하는 2차원 배열
adj = [[0]*(V+1) for x in range(V+1)]
# 인접 행렬에 노드 정보 넣기
for i in range(0, E*2, 2):
s = edges[i]
e = edges[i + 1]
adj[s][e] = 1
adj[e][s] = 1
def bfs(v):
# BFS는 먼저 방문한 노드가 먼저 버려지므로 queue를 사용한다.
queue = [v]
visited = [False] * (V+1)
visited[v] = True
while queue:
front = queue.pop()
# queue에서 가장앞에 있는 정점을 방문
print(front, end=" ")
# 해당 정점에서 방문할 수 있는 모든 경로를 queue에 차곡차곡 넣어준다
for i in range(1, V+1):
if adj[front][i] and not visited[i]:
queue.append(i)
visited[i] = True
bfs(1)



최근댓글